

Los grandes modelos de IA empatan en un nuevo benchmark global
Un índice independiente detecta una “meseta fronteriza” en la IA: GPT-5.2, Claude Opus 4.5 y Gemini 3 Pro convergen en desempeño general.

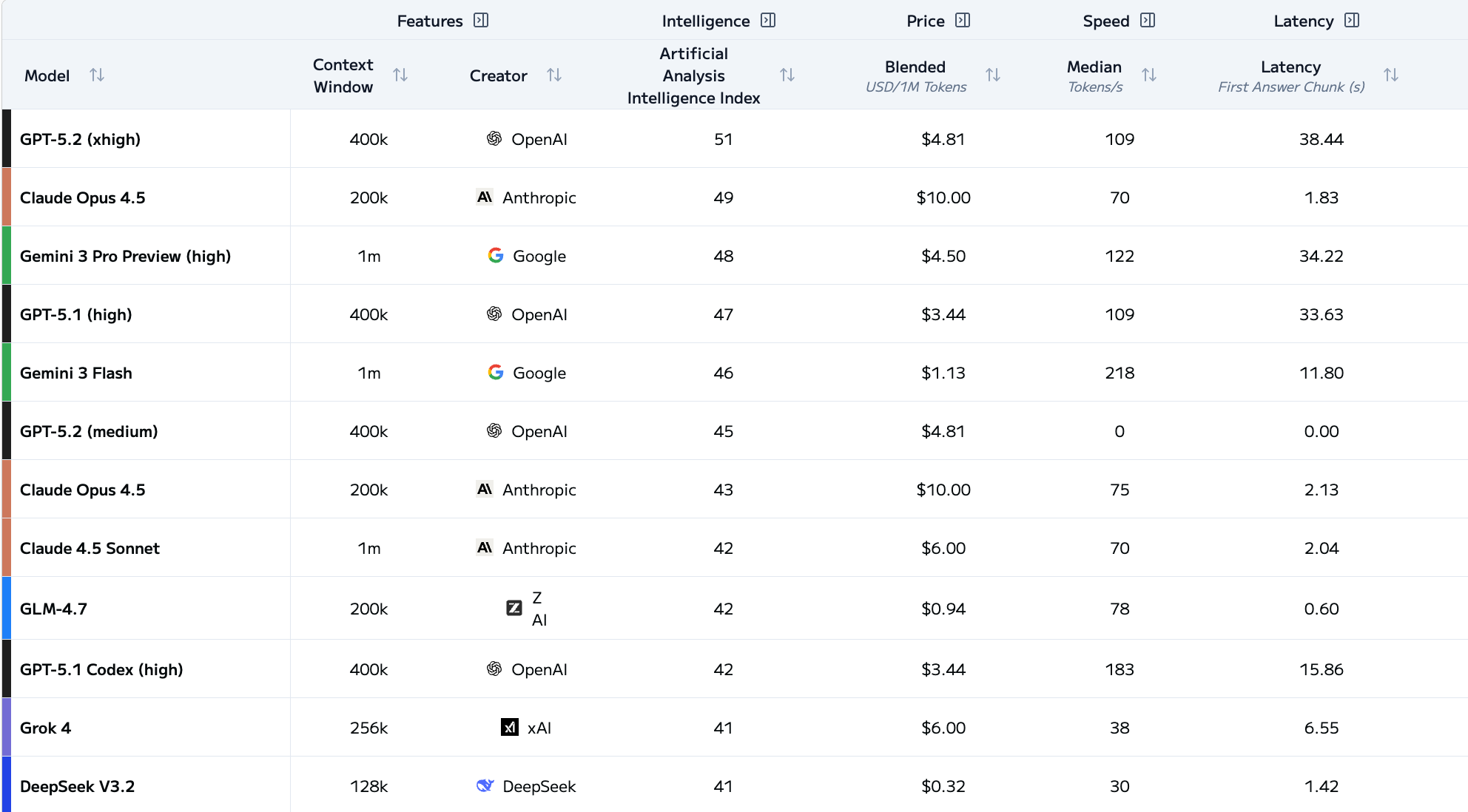
El desarrollo de la inteligencia artificial de frontera parece haber entrado en una nueva fase. Artificial Analysis, firma independiente de evaluación de modelos de IA, publicó esta semana su Intelligence Index v4.0, que por primera vez muestra un empate estadístico entre los principales modelos de lenguaje del mundo.
En la medición, GPT-5.2 de OpenAI obtuvo 50 puntos, seguido muy de cerca por Claude Opus 4.5 de Anthropic con 49 puntos, y Gemini 3 Pro de Google con 48 puntos. La organización define este resultado como una “meseta fronteriza”: un momento en el que los avances continúan, pero ya no se traducen en saltos abruptos dentro de los rankings.
El fin de la carrera por el primer lugar
De acuerdo con Artificial Analysis, la convergencia marca el cierre de un ciclo de rápida rotación en las clasificaciones que dominó 2024 y 2025. Para reflejar mejor el progreso real, el índice v4.0 recalibró sus escalas, reduciendo la puntuación máxima de 73 a 50 puntos e incorporando nuevas pruebas,…
